As I mentioned weeks ago in our CI meeting notes topic, after the recent migration to a new Kubernetes cluster running K3s v1.30, we are no longer able to constrain the resources (CPU & RAM) consumed by the CE workloads. The technical details of why this is the case are fairly esoteric and so I’ll explain if anyone is interested, but the relevant issue is that the lack of resource constraints puts our computing cluster’s stability at risk when under heavy use.
Previously, we could place the limits on the task workers themselves (effectively at the relevant level of the compute node), which meant that we could set high concurrency for high throughput without sacrificing performance, since some tasks consume less CPU and some more, with a dynamic distribution of CPU use depending on workflows at the moment.
![]() The good news is that I found a relatively painless way to recover resource limit enforcement by using the options supported by the Docker service that actually executes our MUSES module containers when workflows are executed.
The good news is that I found a relatively painless way to recover resource limit enforcement by using the options supported by the Docker service that actually executes our MUSES module containers when workflows are executed.
![]() The bad news is that moving the resource limit enforcement down to the individual workflow task level means that we are forced to balance task throughput against task performance for each module.
The bad news is that moving the resource limit enforcement down to the individual workflow task level means that we are forced to balance task throughput against task performance for each module.
The diagram below illustrates the issue:
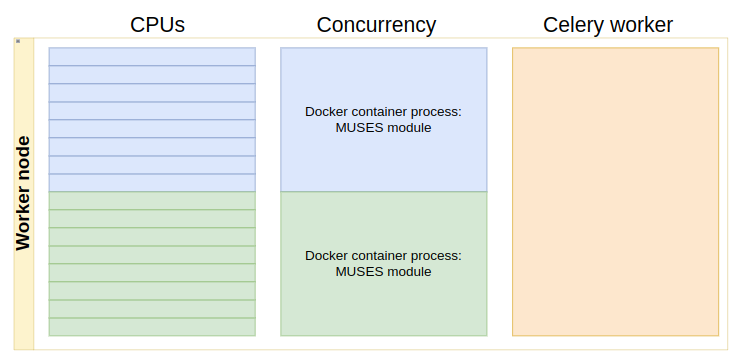
In this example, we run a single task worker on each cluster node, and we allow that task worker to run up to 2 concurrent tasks (i.e. MUSES modules). Since each cluster node has 16 cpu, then we can set a limit of 8 cpu per task. Thus, since our cluster has 10 worker nodes, we could run up to 20 workflow tasks in parallel.
The diagram below depicts a different balance:
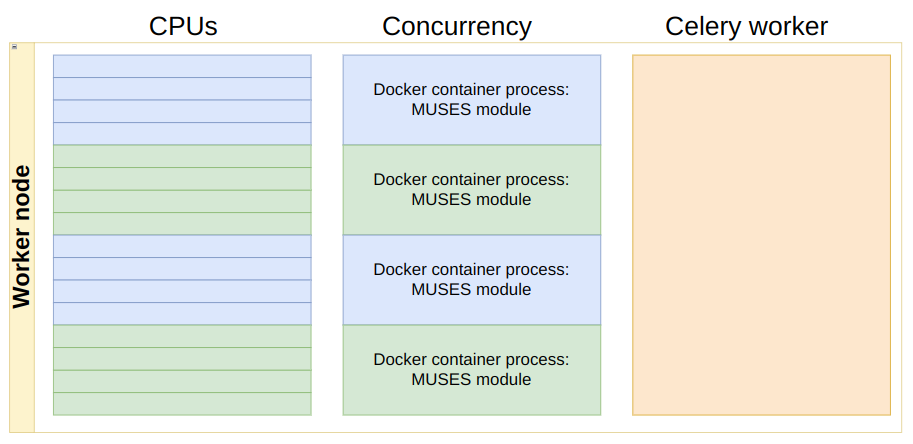
Here, we double the task throughput to 40 concurrent tasks, but at the expense of a maximum of 4 CPUs available to each task.
We know that some MUSES modules are designed to use no more than 1 CPU while others are written to run multicore. It is possible to improve the cluster utilization by assigning certain module tasks to specially configured task workers. For example, perhaps 6 of the 10 task workers (queue “A”) are configured to run with concurrency 16 and CPU limit 1, so that for low-cpu modules, these workers are high-throughput. 2 of the 10 workers (queue “B”) are configured to have concurrency 4 with CPU limit 4, and the remaining 2 of the 10 workers (queue “C”) are configured to have concurrency 2 with CPU limit 8. This kind of multi-queue configuration would require adding more information to the CE config for each registered MUSES module: namely, the max CPU and memory the module expects to use.
For now I plan to implement the new limit enforcer and deploy as soon as I can to hopefully ensure cluster stability by the time we have our MUSES meeting and more people are using the service. @jakinh We should discuss this issue at the meeting and decide how to proceed.