Attendees: @jakinh @andrew.manning
CI Meeting (2021/12/01)
Our discussion focused on determining what are the most constructive components to build first for the Calculation Engine (CE). Because it is infeasible to enforce a consistent environment for all components of the CE, including the EoS and User modules as well as infrastructure-level components, the lowest-level deployment methods for the CE will likely be via Docker Compose. This plan is consistent with our proposal, where we outline three use cases we hope to support:
We plan to support a range of deployment methods for components in the MUSES CI. On the lowest end, people might deploy the core MUSES EoS package on their local workstation in the form of a standard library module in their chosen programming language; for example, there may be a module implementing the MUSES API in Python that someone could import for use in their own code.
This lowest-level use case demands that the user reconcile the various dependencies of their own code and those of the MUSES packages. While this method of execution of MUSES code may be the most familiar to the scientists who will use it, the environment configuration will likely be a challenge (and is almost certainly impossible to solve for the entire CE without containerization).
This brings us to the container-based solution we will promote:
On the highest end, an organization could deploy the entire MUSES CI including all the available services on their own Kubernetes cluster for a independent, self-hosted solution. In between these extremes, we may support deployment of essential components of the CI via a container system like Docker Compose, such that someone could run the web interface locally on their laptop if they prefer something similar to a traditional desktop application.
This approach is not only technically compelled due to the environment and dependency issues mentioned above, it is also the approach that makes efficient use of our limited developer resources. We are definitely delivering a Kubernetes-based web service that provides a multi-user platform for researchers to run asynchronous EoS calculations on high-performance computers; given that, we are already developing the containers for the various system components. Hence, any simpler deployments of the MUSES code that can leverage these same components is desirable.
Feedback from the MUSES community is critical to our success here, because we are clearly balancing the needs of our developers with what actual scientists find useful and accessible. Underlying all of these developments will be robust documentation, including tutorials and articles that introduce concepts at an appropriate level.
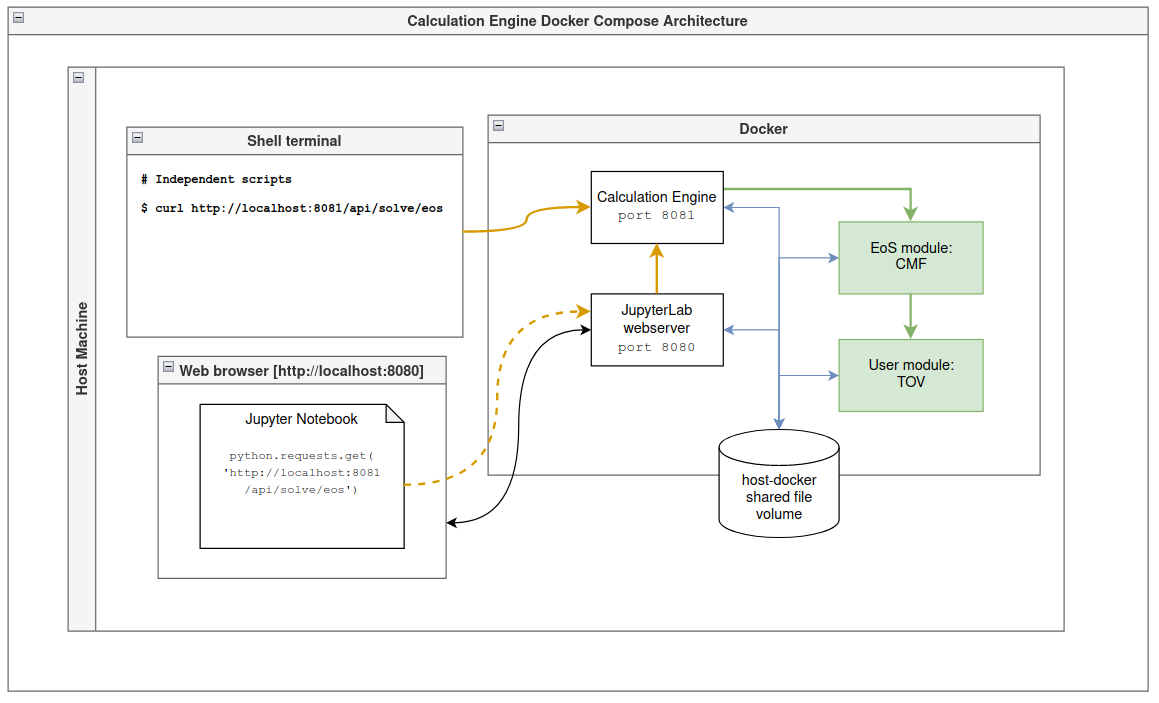
@mhippert and I had a productive meeting today, where we did some brainstorming about the structure of the Calculation Engine that will run on researchers’ local machines. The diagram below captures the essence of our idea so far:
The details are still vague, but the concept is that a researcher will download a repo of files, something like
git clone muses-calculation-engine
in which there are some example Jupyter notebooks and scripts as well as a Docker Compose file:
$ cd muses-calculation-engine
$ ls -l
Readme.md
docker-compose.yaml
notebooks/
notebooks/example.ipynb
scripts/
scripts/muses_cli
They launch the system by running
$ docker-compose up -d
Once the Docker images download and start running, they can open their browser to http://localhost:8080 where they would open one the notebooks/example.ipynb Jupyter notebook.
Alternatively they could run commands in a local terminal using their own scripts and commands to communicate with the CE directly as shown in the diagram where the shell command
$ curl http://localhost:8081/api/solve/eos
is used. (This is nearly identical to what the Jupyter notebook is doing; the difference is in the HTTP request origin: in the notebook case the HTTP request originates from the Jupyter server, and in the local script case they originate from the host operating system.)
Thus, you could create a CLI interface with instructions for running calculations like so:
./scripts/muses_cli --eos-module cmf --input inputs/config.yaml --user-module tov
@jakinh
1 Like
One of our ideas is to leverage Jupyter notebooks as much as possible to bootstrap a user interface as efficiently as possible. The choice is motivated by many reasons, not the least of which is that Jupyter notebooks provide the robust programming environment researchers need to get real science done. The problem is that we also want an interface friendly to those less technically adept or who have less time but still need to utilize more basic MUSES use cases.
It is possible for us to “crowd-source” a graphical interface embedded within a Jupyter notebook running directly in the browser. The article below describes how to build a fairly sophisticated GUI from interactive widgets. Since Jupyter notebooks are so easily shared, we are hoping that as people improve or add features to their notebooks, we can incorporate the additions into our published “official” notebooks that the project will maintain.
https://towardsdatascience.com/bring-your-jupyter-notebook-to-life-with-interactive-widgets-bc12e03f0916
The alternative is of course a standard web app available at a static URL that is developed and deployed exclusively by the MUSES developers. We will probably end up with some balance of the two.
1 Like
The prototype is beginning to take shape. Today we saw a little development milestone by demonstrating the Docker-in-Docker (DinD) technique that will be used to run containerized EoS modules within the primary CE container.
There is a Docker Compose file that defines three containers:
- CE (API webserver)
- CE database (mariadb/mysql)
- JupyterLab (user interface)
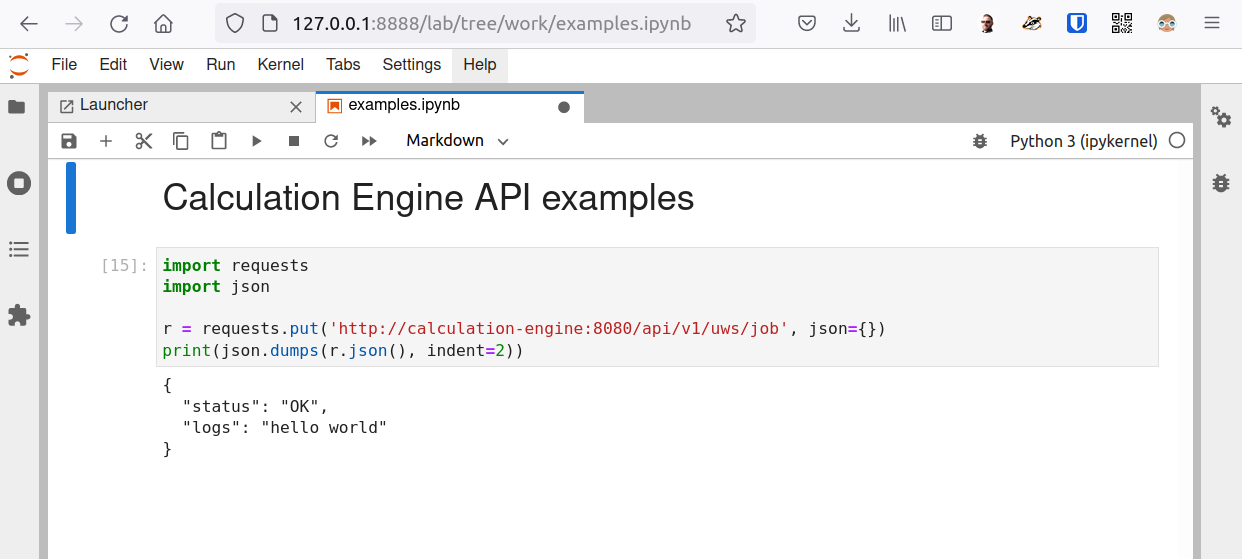
The CE container runs in a privileged mode allowing it to run its own Docker containers. The screenshot below shows the Jupyter notebook accessed at http://127.0.0.1:8888/lab/tree/work/examples.ipynb after running docker-compose up to launch the system.
The HTTP request shown is a PUT request to an endpoint that starts a “job”. The API endpoint triggers the CE to spawn a Docker container (see code snippet below) using the Docker SDK for Python.
class JobHandler(BaseHandler):
def put(self):
client = docker.from_env()
client.containers.run("ubuntu:20.04", "echo hello world", detach=True)
container_list = client.containers.list()
for container in container_list:
log.debug(container.id)
logs = []
for line in container.logs(stream=True):
logs.append(line.strip().decode('utf-8'))
log.debug(logs[-1])
self.send_response({
'status': 'OK',
'logs': '\n'.join(logs),
})
self.finish()
Note that the CE system containers interact over the network in a very similar way in which they will communicate when running in the Kubernetes environment of the full hosted platform.
The initial code can be found in NSF MUSES / Calculation Engine · GitLab.
1 Like
To demonstrate a rudimentary calculation spec and output retrieval procedure, we’re going to use @mhippert 's fledgling BH_EoS module to run a “real EoS calculation”. That module is containerized with an image in the GitLab project container registry that can be pulled, and one of the example commands takes five seconds to complete, which is good for testing.
We are more or less immediately confronted with implementing the job management system, because we will need another API endpoint to check the status of the submitted calculation job and then fetch the results using a third API endpoint when it completes. This can be the vehicle to propel development of an abstraction layer we will need soon when Delta is available; namely, the locally running CE prototype is using a Docker container to run the job, which is a different mechanism from the Kubernetes Job system that we have already demonstrated.
In other words, we have three different environments in which calculation jobs will execute:
- On local end-user workstations as a Docker-in-Docker container
- In a Kubernetes cluster as a Kubernetes Job
- On NCSA Delta GPU compute nodes
These three environment should be supported in as unified a codebase as possible given our limited developer resources.
One of the advantages in unification might be that researchers could launch remote jobs on our Kubernetes cluster or Delta from their locally running CE just as easily as they could via the web app we will host at musesframework.io. This would allow them to blend the compute backends as best suits their work. For example, someone may run several smaller jobs locally but then launch the last one remotely because they want to let it run while they commute home (during which time their laptop workstation is offline in their backpack).